A Necessary Critique of Fontcuberta’s Algorithmic Photography

This March, Spanish conceptual artist and photographer Joan Fontcuberta published a new book in Italy. Immagini Latenti concludes with a chapter on AI and photography, referencing the debates surrounding Boris Eldagsen’s submission of an AI-generated image to the Sony World Photography Awards in 2023 and Miles Astray’s submission of a photograph in the AI category of the 1839 Award in 2024.
When we received our copies, we were struck by the context in which our images appeared. Fontcuberta frames AI-generated images as “Second-Generation Photography” and proposes the term “Algorithmic Photography”.
Over the past 2.5 years, we have repeatedly encountered similar lines of reasoning. They are not only logically inconsistent, but they are also unhelpful, both for photography and for democratic societies. For that reason, we find it necessary to respond collectively to what we consider a rudimentary theory. Below, we contrast excerpts from the book (used with permission) with our own perspective. The original Italian text has been translated into English using multiple AI tools (ChatGPT, Gemini, DeepL).

I. The Naming Problem
Joan Fontcuberta:
When I got married, some friends gave me a lemon tree […] We planted it and it grew happily. […] after twenty-five years […] the lemon tree began to produce oranges. […] A friend who is an expert in citrus fruits […] gave me a plausible explanation, […] our lemon tree had almost certainly been grafted onto a branch of an orange tree, and over time it began to reveal its true hybrid nature—non-binary and ambivalent.
Personally, I preferred to keep thinking that the tree had found the courage to come out of the closet. All the more so because it seemed to me a magnificent metaphor for what is happening to photography today, which is also going through a phase in which it is about to come out.
Let me explain. For two centuries, we have attributed to photography a descriptive accuracy of reality that guaranteed absolute documentary fidelity. Now, however, algorithmic photography is blending with optical photography, and we no longer know which way to turn.
Immediately, we encounter a semantic and terminological problem. There are photographic images produced by cameras and photo-optical recording systems. And there are others—apparently photographic—produced through generative AI visualization systems.
The former are children of chemistry and light; the latter of computing and darkness. We must therefore begin to decide whether both types of image should be considered photographic.
If we focus on the processes involved, it is obvious that they are different kinds of images. Yet the difficulty of finding a word capable of classifying photorealistic representations of algorithmic origin weakens the decisiveness of that answer.
These are images without a real referent—what we might call nemotypes.
Some have proposed the term promptography, because such images originate from a prompt—that is, natural-language instructions given to a system in order to obtain the desired photographic result.
There have been other attempts, such as syntography, but none have prevailed.
When photography was shaken by the arrival of digital technology, it became necessary to specify that there had been a previous form to which a distinguishing adjective was now added: we had analog photography—or photochemical photography—versus digital photography. At that time, there was no need to invent or assign a specific new name, and nothing disastrous happened. Therefore, we could probably proceed in the same way now and still understand one another perfectly.
Boris Eldagsen:
Fontcuberta clearly recognizes the distinction between camera-made and AI-generated images at the level of process – but then argues that this distinction ultimately does not matter.
The problem is: it matters. Considerably.
A photograph is made by light bouncing off a real thing and hitting a sensor. An AI image is made by a computer calculating what a plausible image would look like, based on patterns learned from millions of prior examples. The outputs may appear identical on screen, but they emerge from fundamentally different processes. And it is precisely this process that grants photography its authority as evidence.
Calling AI images “Algorithmic Photography” treats this as a minor upgrade: a lemon tree simply producing oranges. But even in Fontcuberta’s own metaphor, a lemon is still a lemon and an orange is still an orange. Grafting doesn’t change what a fruit is. Two entirely different kinds of image are being given the same name, and that confusion has real consequences.
By this logic, a photorealistic painting would become “Acrylic Photography”. But we still call it painting, because the process matters, and it has been created with canvas, brushes, and paint.
Arguing that the lack of an adequate term for “photorealistic representations of algorithmic origin” justifies subsuming AI images under photography is weak. On the one hand, naming a new medium takes time. On the other hand, Fontcuberta remains confined within photographic thinking and fails to recognize what this new medium actually is: LATENT SPACE.
It consists of the training data of an AI model in which all media is encoded as vectors. In Latent Space, different art forms are no longer separate materials. They become different projections of the same underlying structure. A melody can morph into an image. A text description can generate a video. A sketch can become a sculpture. Latent space is a meta-medium.
This is why prompts have become multimodal. The prompt is a control interface to latent space, navigating probability.
And that is precisely why I suggested the term “promptography”. It encompasses everything produced with a prompt: text, sound, video – not just images resembling photography, but also those resembling drawing or painting.
Because Fontcuberta limits his analysis to “photorealistic representations”, he reduces the discussion to a narrow subset of outputs—and consequently struggles with the arguments that follow.
Miles Astray:
Read Miles’ response on his webpage (link will follow soon).

II. The DNA Problem
Joan Fontcuberta:
[…] But the debate goes deeper: are we dealing with images belonging to different classes, or simply photographs of different rank?
[…] It is easy to imagine that everyone dreamed of inventing a technique capable of producing faithful representations independent of human skill—as if nature could represent itself without the mediation of pencil or brush.
The camera eventually fulfilled that role, producing rigorous and detailed visual records. Since then, billions of photographs have been produced, and these images now constitute the very material used to train generative neural networks.
In fact, AI functions like an ogre forced to devour enormous quantities of images in order to produce plausible results.
Thus, algorithmic photographic images, although derived from the visual heritage of the entire history of photography, carry an undeniable photographic DNA. For this reason, they could reasonably be considered second-generation photographs.
Roland Barthes once wrote that every photograph awaits a text. Now the situation is reversed: it is the text that generates the photograph.
Boris Eldagsen:
Fontcuberta’s “Barthes reversal” is rhetorically appealing but conceptually shallow. In Camera Lucida, Roland Barthes argues that photographs are unstable without language. The caption stabilizes the photograph. The same photo will change its meaning with different captions.
But Fontcuberta overlooks a crucial development: prompts are not captions. They are instructions to a probabilistic system. Moreover, it is no longer simply “text” generating images. Multimodal prompting has been standard for years. Any input modality can generate any output modality within latent space. What collapses here is media categories.
The “Second-Generation Photography” argument is elegant, but it rests on a logical error. AI models are trained on millions of photographs: that’s true. But that doesn’t make their outputs photography. What the model inherits is visual style, a set of statistical patterns. It does not inherit what defines photography: a direct physical relationship between light, a real event, and a sensor.
Miles Astray:
Read Miles’ response on his webpage (link will follow soon).

III. The Validation Problem
Joan Fontcuberta:
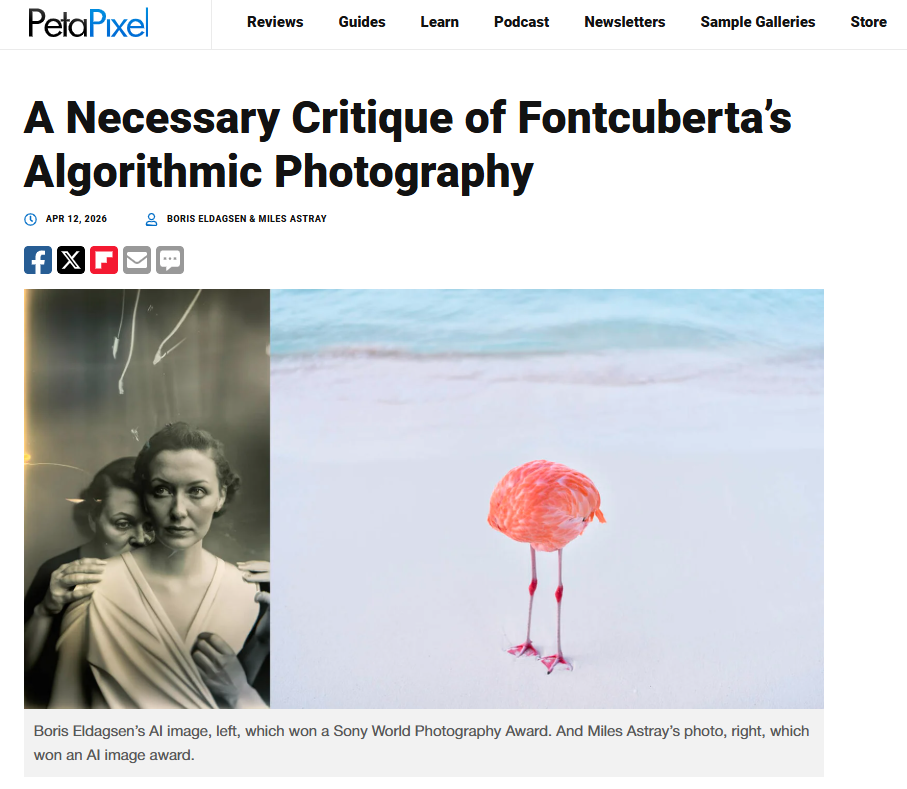
This terminological issue—behind which lies a deeper ontological question—came to the attention of the media when the work The Electrician, belonging to the series Pseudomnesia by the German photographer Boris Eldagsen, won the Sony World Photography Award 2023 in the “Creative” category. […]
The Canadian photographer Miles Astray, specializing in nature and travel photography, reversed the logic of Eldagsen’s action: he submitted a real photograph to the newly created AI-image category of another important competition, the Color Photography Awards.[…]
Indeed, both cases highlight an uncomfortable but unavoidable reality: the dividing line between human creation and that generated by artificial intelligence is rapidly fading, if it has not already disappeared entirely. […] Their intention was to reveal the unreliability of validation systems in competitions of this kind.
These may have been minor infractions, but they pointed toward a much more crucial issue: determining the status and labeling of images, their lineage, their pedigree.
Both initiatives might appear as provocations, but in reality, they offered a necessary critique: if a photograph taken with a camera can be mistaken for an image generated by a machine – or vice versa – then we must rethink how we define the boundaries between images, and also concepts of authorship, creativity, and visual truth. Rather than making us victims of deception, these gestures provide a useful conceptual shock.
Boris Eldagsen:
What these two incidents actually exposed is that the institutions evaluating the images had no coherent framework for telling them apart.
If these cases teach us anything, it is this: the credibility of an image can no longer reside in the image itself. It must reside in the process—who made it, how, and under what conditions of accountability. Documentary authority does not disappear; it migrates. It becomes procedural.
This is precisely why Fontcuberta’s dismissal of process is problematic.
Miles Astray:
Read Miles’ response on his webpage (link will follow soon).

IV. The Doubt Problem
Joan Fontcuberta:
Despite everything, the fundamental issue that troubles both specialists and the public concerns the credibility of images.
Some wonder whether a prompt-generated photograph will one day win the World Press Photo award. But perhaps the question is wrongly framed.
What should really be questioned is whether competitions like the World Press Photo still make sense.
We now live in a visual regime in which images increasingly construct the world rather than simply represent it.
[…] Perhaps we should even be grateful for their proliferation, because they remind us of the necessity of doubt.
Algorithmic photography reinforces the idea that every image is, inevitably, an illusion and forces us to reconsider the trust we place in images.
[…] Photography, therefore, has never truly been objective; we simply chose to believe that it was.
Today, with AI acting as a new demiurge, documentary photography quietly slips between historical narrative and fabricated illustration.
Deepfake technologies have opened Pandora’s box of iconography: thousands of hyperreal scenes and faces created from nothing flood our screens.
We no longer look in order to understand—we look in order to doubt.
[…] Every technology of vision has reshaped how we perceive the world.
What we are witnessing today is the transition from optical realism to informational realism—a synthetic realism summoned by commands, texts, and strings of code.
From Greek realism, to Renaissance perspective, to Enlightenment aspirations for accuracy, we have suddenly arrived at a condensed synthesis of all these visual regimes.
And now a single prompt can generate an image that might once have required centuries of technological evolution.
Boris Eldagsen:
The claim that “every image has always been a fiction” is only half true—and half-truths are dangerous in public discourse.
Every photograph is framed, selected, edited – that’s undeniable. But a camera photograph still begins with something real: light from an actual event, recorded by a sensor. A generated image begins with statistical inference across a database of prior images. These are not the same act.
Treating them as equivalent doesn’t sharpen our critical thinking. Eliminating institutions like World Press Photo does not solve the problem either. The real task is to defend accountability: where an image comes from, who produced it, and under what conditions.
Trust is shifting—from the image to the process. Provenance, metadata, editorial chains of custody, and transparent sourcing become central. The image is no longer proof. The process is.
What is striking is that Fontcuberta does not address the democratic implications of this shift in this chapter. Public discourse depends on visual evidence. When all images become equally suspect, societies lose a crucial epistemic tool.
Doubt, in moderation, is productive. In excess, it becomes disorienting – and disorientation is easily exploited.
If any image can simulate evidence of events that never occurred, those who benefit most are those least deserving of trust. Blurring the distinction between photographic capture and synthetic generation does not liberate us from naivety. It provides cover for manipulation.
When visual evidence becomes a category of general suspicion, the burden of proof shifts in ways that favour those in power and disadvantage those trying to hold them accountable.
The answer is not to celebrate doubt as an end in itself. The answer is to construct new distinctions: between capture and synthesis, between enhancement and invention, between evidence and illustration—and to build institutions capable of maintaining those distinctions.
Miles Astray:
Read Miles’ response on his webpage (link will follow soon).
About the authors: Boris Eldagsen is a Berlin-based photo & video artist, investigating the unconscious mind. In search of the timeless, his visual poetry unites the sublime and the uncanny. You can find more of his work on his website, Facebook, YouTube, and Instagram.
Miles Astray is an activist artist blending writing and photography inspired by slow travel. You can find more of his work on his website and Facebook.
Responses: Gregory Chatonsky
Read his rebuttal to our rebuttal and my rebuttal to his rebuttal-rebuttal: www.eldagsen.com/chatonsky